 phildini.dev
phildini.dev
My Open Source Workflow
I think people have an impression that I make lots of contributions to Open Source (only recently true), and that therefore I am a master of navigating the steps contributing to Open Source requires (not at all true).
Contributing to Open Source can be hard. Yes, even if you’ve done it for a while. Yes, even if you have people willing to help and support you. If someone tries to tell you that contributing is easy, they’re forgetting the experience they’ve gained that now makes it easy for them.
After much trial and error, I have arrived at a workflow that works for me, which I’m documenting here in the hopes that it’s useful for others and in case I ever forget it.
Let’s say you want to contribute to BeeWare’s Batavia project, and you already have a change in mind. First you need to get a copy of the code.
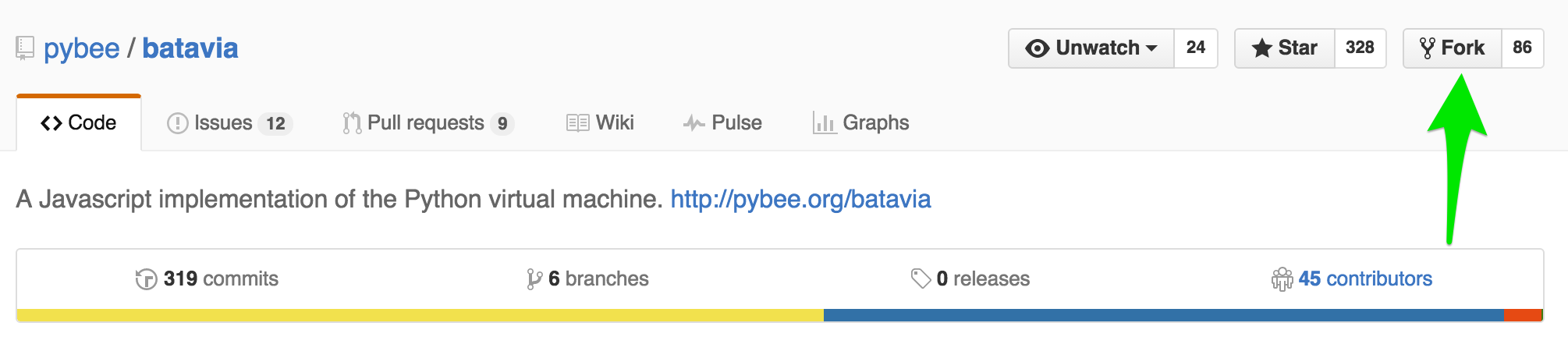
I usually start by forking the repository (or “repo”) to my own account. “Forking” makes a new repo which is a copy of the original repo. Once you fork a repo, you won’t get any more changes from the original repo, unless you ask for them specifically (more on that later).
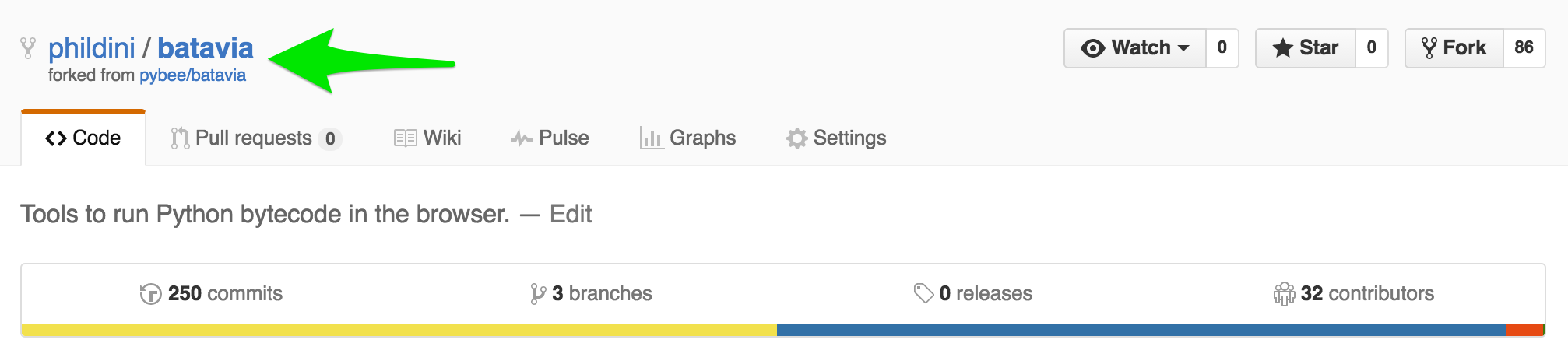
Now I have my own copy of the batavia repo (note the phildini/batavia instead of pybee/batavia)
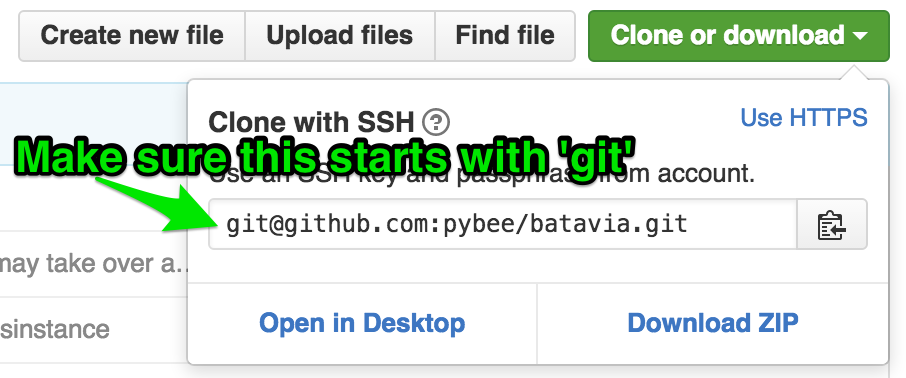
To get the code onto my local machine so I can start working with it, I open a terminal, and go to the directory where I want to code to live. As an example, I have a “Repos” directory where I’ve checked out all the repos I care about.
cd Repos
git clone [[email protected]](/cdn-cgi/l/email-protection):phildini/batavia.gitThis will clone the batavia repo into a folder named batavia in my Repos directory. How did I know what the URL to clone was? Unfortunately, GitHub just changed their layout, so it’s a bit more hidden than it used to be.
Now we have the code checked out to our local machine. To start work, I first make a branch to hold my changes, something like:
git checkout -b fix-class-typesI make some changes, then make a commit with my changes.
git commit -avThe -a flag will add all unstaged files to the commit, and the -v flag will show a diff in my editor, which will open to let me create the commit message. It’s a great way to review all your changes before you’ve committed them.
With a commit ready, I will first pull anything that has changed from the original repo into my fork, to make sure there are no merge conflicts.
But wait! When we forked the repo, we made a copy completely separate from the original, and cloned from that. How do we get changes from the official repo?
The answer is through setting up an additional remote server entry.
If I run:
git remote -vI see:
origin [[email protected]](/cdn-cgi/l/email-protection):phildini/batavia.git (fetch)
origin [[email protected]](/cdn-cgi/l/email-protection):phildini/batavia.git (push)Which is what I would expect — I am pulling from my fork and pushing to my fork. But I can set up another remote that lets me get the upstream changes and pull them into my local repo.
git remote add upstream [[email protected]](/cdn-cgi/l/email-protection):pybee/bataviaNow when I run:
git remote -vI see:
origin [[email protected]](/cdn-cgi/l/email-protection):phildini/batavia.git (fetch)
origin [[email protected]](/cdn-cgi/l/email-protection):phildini/batavia.git (push)
upstream [[email protected]](/cdn-cgi/l/email-protection):pybee/batavia.git (fetch)
upstream [[email protected]](/cdn-cgi/l/email-protection):pybee/batavia.git (push)So I can do the following:
git checkout master
git pull upstream master --rebase
git push origin master --force
git checkout fix-class-types
git rebase masterThese commands will:
- Check out the master branch
- Pull changes from the original repository into my master branch
- Update the master branch of my fork of the repo on GitHub.
- Checkout the branch I’m working on
- Pull any new changes from master into the branch I’m working on, through rebasing.
Now that I’m sure my local branch has the most recent changes from the original, I push the branch to my fork on github:
git push origin fix-class-typesWith my branch all ready to go, I navigate to https://github.com/pybee/batavia, and GitHub helpfully prompts me to create a pull request. Which I do, remembering to create a helpful message and follow the contributing guidelines for the repo.
That’s the basic flow, let’s answer some questions.
Why do you make a branch in your fork, rather than make the patch on your master branch?
- GitHub pull requests are a little funny. From the moment you make a PR against a repo, any subsequent commits you make to that branch in your fork will get added to the PR. If I did my work on my master, submitted a PR, then started work on something else, any commits I pushed to my fork would end up in the PR. Creating a branch in my fork for every patch I’m working on keeps things clean.
Why did you force push to your master? Isn’t force pushing bad?
- Force pushing can be very bad, but mainly because it messes up other collaborator’s histories, and can cause weird side effects, like losing commits. On my fork of a repo, there should be no collaborators but me, so I feel safe force pushing. You’ll often need to force push upstream changes to your repo, because the commit pointers will be out of sync.
What if you need to update your PR?
- I follow a similar process, pulling changes from upstream to make sure I didn’t miss anything, and then pushing to the same branch again. GitHub takes care of the rest.
What about repos where you are a Core Contributor or have the commit bit?
- Even when I’m a Core Contributor to a repo, I still keep my fork around and make changes through PRs, for a few reasons. One, it forces me to stay in touch with the contributor workflow, and feel the pain of any breaking changes. Two, another Core Contributor should still be reviewing my PRs, and those are a bit cleaner if they’re coming from my repo (as compared to a branch on the main repo). Three, it reduces my fear of having a finger slip and committing something to the original repo that I didn’t intend.
That’s a good overview of my workflow for Open Source projects. I’m happy to explain anything that seemed unclear in the comments, and I hope this gives you ideas on how to make your own contribution workflow easier!